周末造轮子:写了一个 LLM API Key 本地负载均衡器
最近因为一直在高强度使用各种 LLM 服务(OpenAI, Gemini, DeepSeek 等),遇到了一个很现实的痛点:贫穷。
为了省钱,我申请了多个免费的 API Key(比如 Google Gemini 的 Free Tier,或者 DeepSeek 的赠送额度),但这些免费 Key 往往有严格的速率限制(RPM/TPM)。写代码写得正嗨,突然弹出一个 429 Too Many Requests,思路瞬间被打断,非常搞心态。
场景与需求
我的需求很简单:
- 多 Key 轮询:我有好几个 Key,希望能自动轮着用,这个限流了自动切下一个。
- 统一入口:我不想在每个 Client(Chatbox, Cursor, VSCode 插件)里分别填一堆 Key。我希望只填一个统一的 url,后端自动帮我处理复杂的鉴权和路由。
- 兼容性:必须完全兼容 OpenAI 格式,因为现在几乎所有工具都支持 OpenAI 协议。
- 可视化:我想知道哪个 Key 用得多,哪个 Key 经常报错,哪个 Key 还在冷却中。
市面上有很多强大的网关(如 OneAPI, NewAPI),但它们太重了。我不需要用户系统,不需要充值渠道,不需要复杂的数据库。我只需要一个跑在本地的小工具,最好是一个单一的可执行文件,甚至是一个 macOS App。
于是,趁着周末,我写了一个小工具:llm-api-lb。
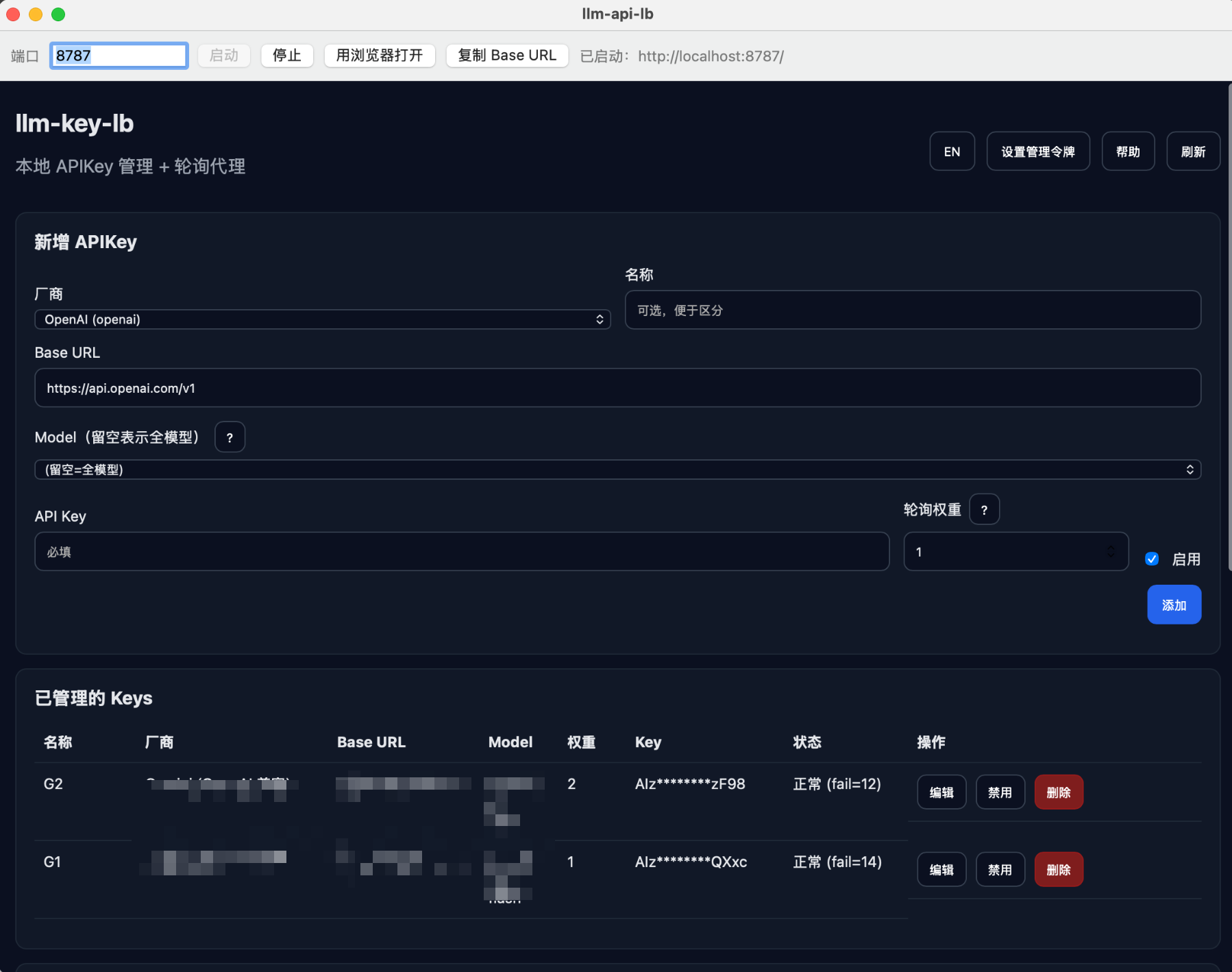
灵感与设计
核心思路其实就是一个反向代理(Reverse Proxy)。
- 拦截:拦截所有发往
/v1/*的请求。 - 调度:在内存里维护一个 Key 列表,包含每个 Key 的状态(是否启用、是否在冷却中、失败次数等)。
- 转发:挑一个可用的 Key,替换掉请求头里的
Authorization,转发给上游(OpenAI/Google/DeepSeek)。 - 容错:如果上游返回 429 或 5xx,标记该 Key 进入“冷却期”,并自动重试下一个 Key。
技术栈选择了最简单的 Node.js + Express。
为什么不用 Go 或 Rust?因为我想顺便写一个简单的 Web 管理界面,Node.js 处理 HTTP 和 JSON 实在是太顺手了,而且配合 pkg 打包成单文件也非常方便。
实施过程
1. 核心逻辑
核心逻辑不到 1000 行代码。最关键的部分是“选 Key”和“错误处理”。
我实现了一个简单的 Round-Robin(轮询)算法,但加了被动冷却机制。一旦某个 Key 请求失败(429 限流或 401 鉴权失败),它会被暂时“关小黑屋”一段时间(比如 1 分钟)。在这 1 分钟内,流量会自动绕过它。
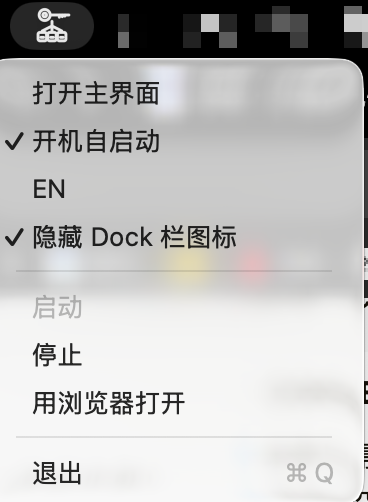
2. 打造 macOS App
我希望它不仅仅是一个黑乎乎的命令行工具,而是一个稍微优雅的 Menu Bar App(菜单栏应用)。
我使用 Node.js 的脚本能力,配合 macOS 的系统命令,实现了一套“伪打包”流程:
- 用
pkg把 Node.js 代码打包成二进制可执行文件。 - 用 Swift 写了一个极简的 Launcher(启动器),负责调用这个二进制,并管理托盘图标和菜单。
- 把它们塞进标准的
.app目录结构里。
遇到的一个坑是端口占用。如果用户电脑上 8787 端口被占了怎么办?
我在 Swift 启动器里加了逻辑:启动前先探测端口,如果被占用了,弹窗提示或自动寻找新端口。
为了体验更好,我还做了菜单栏常驻:点击红叉关闭窗口后,程序其实还在后台运行,随时可以通过顶部菜单栏唤醒。
3. 图标与细节
为了让它看起来像个正经 App,我还专门画了个图标(我的审美很高,但 ChatGPT审美有限)。 遇到的一个小插曲是图标有白边,在 Dark Mode 下很难看。于是又写了个 Python 脚本,用 PIL 库把边缘像素做了透明度处理,终于顺眼了。
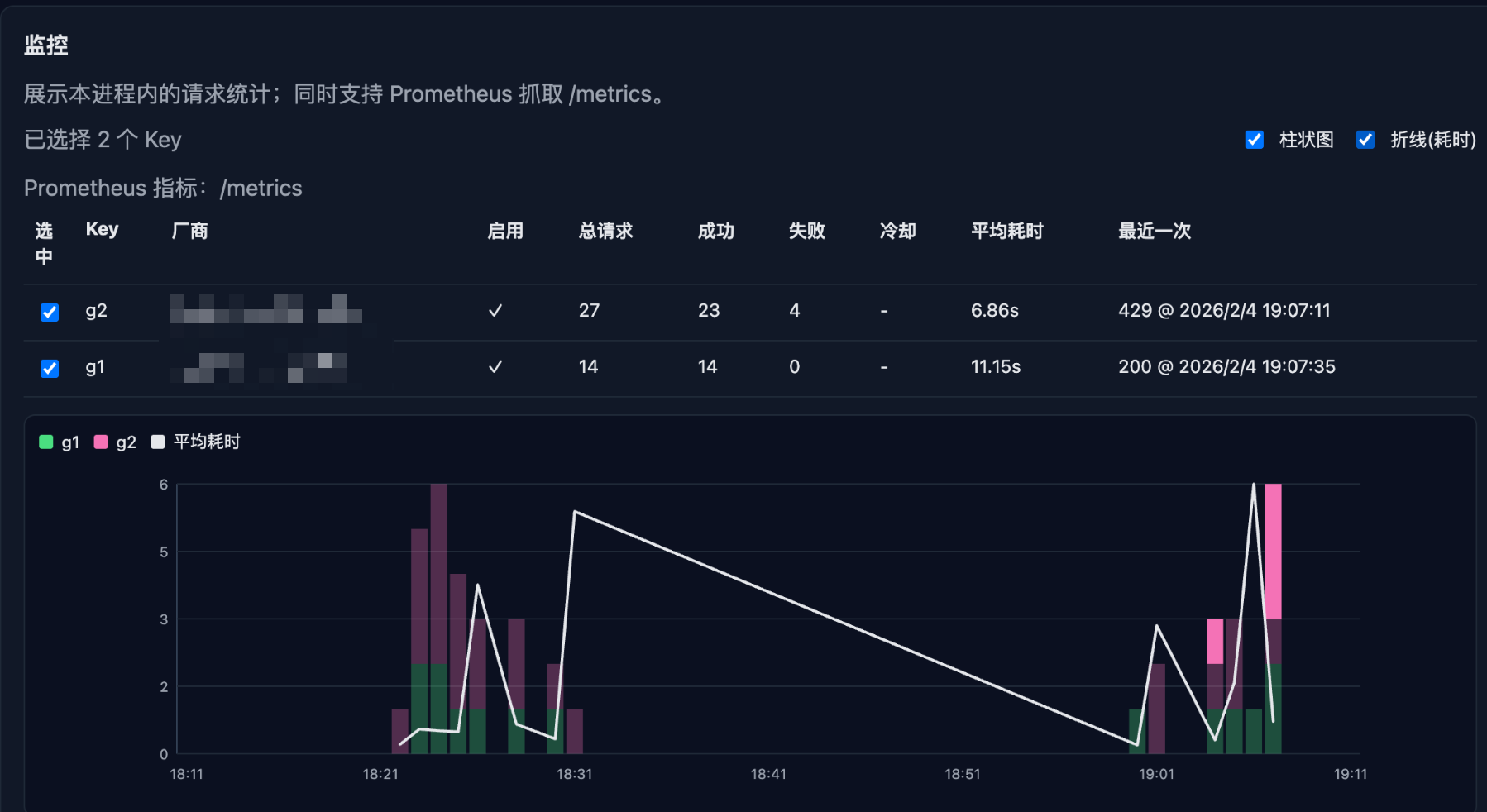
4. 监控与可视化
我在前端加了一个简易的监控面板。
利用 chart.js 画出了每个 Key 的请求量和耗时趋势。看着不同颜色的线条在走,心里有一种莫名的踏实感——我知道我的 Key 们正在努力工作,而且负载被均匀地分摊了。
总结
这个项目本身技术含量不高,但解决了我自己的痛点。
现在我写代码时,Base URL 填本机 http://localhost:8787/v1,Key 随便填一个。后台会自动帮我在 Gemini 的免费额度和 DeepSeek 之间反复横跳, 429 报错少了很多。
如果你也有类似的烦恼,或者对 Node.js 封装桌面应用感兴趣,欢迎去 GitHub 看看源码。
GitHub: https://github.com/weidussx/llm-api-lb
Happy Coding! 🚀