实战 · 打造会记忆的AI 写作搭档(坤):检索系统篇(向量检索、混合检索与云化)
在《实战 · 打造会记忆的AI 写作搭档(一):多 Agent 架构进化》里,我把“多 Agent 如何协作、记忆如何串起来”讲清楚了;在《实战 · 打造会记忆的AI 写作搭档(二):数据库篇(从 JSON 到单库,再到关系表)》里,我把“事实层”从 JSON 到 SQLite 再到关系表的演进复盘了一遍。
但当篇幅变成几十万字以后,真正决定体验的往往不是“数据在不在”,而是“我能不能把它找回来”:查照(出现没出现)、结构化筛选(谁属于谁)、语义联想(像不像、是不是同一种氛围)要同时成立。于是我给 FantasyNovelAgent 加了一个清晰的“索引层”,并把检索从“章节”扩展到“全图谱”。
1. 先把边界说清楚:事实层 vs 索引层
从这里开始,我明确一条底层原则:
事实来源(Source of Truth)=
data/novel.db(结构化数据/元数据/KV/FTS) +data/blob_store/(章节正文对象)。 任何索引、缓存、衍生结构都必须可以从事实来源重建。
这条原则后面会直接决定向量库怎么设计:向量库只能是“索引层”,不能变成“第二套事实来源”。
索引层可以随时重建、可以随模型升级,但不能反过来成为事实锚点。因此我把检索系统做成 sidecar:
- 事实层:
data/novel.db+data/blob_store/ - 索引层:
data/vector_db/(向量库,可重建)
下面这张图是“事实层 vs 索引层”的最小架构视图:
flowchart LR
UI[Streamlit UI] --> CM[ContextManager]
CM -->|读写| DB[(data/novel.db\nSQLite:结构化/KV/FTS/元数据)]
CM -->|读写| BLOB[data/blob_store/\n章节正文对象(按 ulid)]
CM -->|向量索引/检索| VEC[(data/vector_db/\nChromaDB 索引层)]
VEC --> EMB{Embedding 后端\nhf / onnx / openai}
DB -.可重建.-> VEC
BLOB -.可重建.-> VECflowchart LR
UI[Streamlit UI] --> CM[ContextManager]
CM -->|读写| DB[(data/novel.db\nSQLite:结构化/KV/FTS/元数据)]
CM -->|读写| BLOB[data/blob_store/\n章节正文对象(按 ulid)]
CM -->|向量索引/检索| VEC[(data/vector_db/\nChromaDB 索引层)]
VEC --> EMB{Embedding 后端\nhf / onnx / openai}
DB -.可重建.-> VEC
BLOB -.可重建.-> VECflowchart LR
UI[Streamlit UI] --> CM[ContextManager]
CM -->|读写| DB[(data/novel.db\nSQLite:结构化/KV/FTS/元数据)]
CM -->|读写| BLOB[data/blob_store/\n章节正文对象(按 ulid)]
CM -->|向量索引/检索| VEC[(data/vector_db/\nChromaDB 索引层)]
VEC --> EMB{Embedding 后端\nhf / onnx / openai}
DB -.可重建.-> VEC
BLOB -.可重建.-> VECflowchart LR
UI[Streamlit UI] --> CM[ContextManager]
CM -->|读写| DB[(data/novel.db\nSQLite:结构化/KV/FTS/元数据)]
CM -->|读写| BLOB[data/blob_store/\n章节正文对象(按 ulid)]
CM -->|向量索引/检索| VEC[(data/vector_db/\nChromaDB 索引层)]
VEC --> EMB{Embedding 后端\nhf / onnx / openai}
DB -.可重建.-> VEC
BLOB -.可重建.-> VEC2. 向量检索(ChromaDB):把“语义联想”做成可用能力
关系表解决的是“确定性事实”和“结构化查询”。但写作系统还需要解决另一类问题:语义联想。
- “我想写一段背叛后的心灰意冷,给我召回最像的场景”
- “这章提到的‘青云剑’之前出现在哪里?有没有状态变化?”
- “反派 A 的嘲讽口癖是什么?给我找几段最像的对话”
这些问题的共同点是:你很难用一个确定字段来表达它。这就是向量检索存在的意义。
2.1 向量库到底在干什么?
可以把“向量检索”理解为三步:
把文本变成向量(Embedding)
模型会把一段文本映射成一个高维数字列表(比如 384 维或 768 维)。相近含义的文本,向量会更接近。把向量放进索引(Index)
当文本数量多了,不能每次都全量比对。向量库会用近似最近邻索引(常见是 HNSW)让检索变快。查询时把问题也变成向量,然后找“最近的那几段”
这就是“语义检索”:你不需要输入同样的关键词,也能召回含义相近的段落。
一句话总结:
SQL 擅长回答“是什么/有多少/谁属于谁”,向量库擅长回答“像不像/是不是同一种氛围/是不是同一类冲突”。
2.2 工程底线:向量库是可重建的索引层
我坚持的数据原则是:
- 事实来源:
data/novel.db负责结构化数据/元数据/KV/FTS;章节正文在data/blob_store/ - 索引副本:向量库保存的是“分块后的文本副本 + 向量索引”,它的价值是检索速度与语义能力
- 可重建:向量库损坏或模型升级时,可以从事实来源全量重建
因此当前实现采用“sidecar”形态,而不是把 embeddings 直接塞进 novel.db:
- 向量库目录:
data/vector_db/ - ChromaDB 持久化:
data/vector_db/chroma.sqlite3(存元数据/记录) - HNSW 索引文件:
data/vector_db/<uuid>/*.bin(存向量近邻图索引)
把“向量库 sidecar”画出来会更直观:
flowchart TB
subgraph FACT[事实层(Source of Truth)]
DB[(data/novel.db)]
BLOB[data/blob_store/]
DB --> CH[chapters / drafts]
DB --> KV[kv_store]
DB --> REL[关系表(characters/organizations/...)]
end
subgraph INDEX[索引层(可重建)]
VEC[(data/vector_db/)]
VEC --> CHS[chunks: source_type=chapter]
VEC --> ECS[entity_card: 角色/地图/世界观]
VEC --> INF[inference]
VEC --> MYS[mystery]
end
DB -.全量重建/增量更新.-> VEC
BLOB -.全量重建/增量更新.-> VECflowchart TB
subgraph FACT[事实层(Source of Truth)]
DB[(data/novel.db)]
BLOB[data/blob_store/]
DB --> CH[chapters / drafts]
DB --> KV[kv_store]
DB --> REL[关系表(characters/organizations/...)]
end
subgraph INDEX[索引层(可重建)]
VEC[(data/vector_db/)]
VEC --> CHS[chunks: source_type=chapter]
VEC --> ECS[entity_card: 角色/地图/世界观]
VEC --> INF[inference]
VEC --> MYS[mystery]
end
DB -.全量重建/增量更新.-> VEC
BLOB -.全量重建/增量更新.-> VECflowchart TB
subgraph FACT[事实层(Source of Truth)]
DB[(data/novel.db)]
BLOB[data/blob_store/]
DB --> CH[chapters / drafts]
DB --> KV[kv_store]
DB --> REL[关系表(characters/organizations/...)]
end
subgraph INDEX[索引层(可重建)]
VEC[(data/vector_db/)]
VEC --> CHS[chunks: source_type=chapter]
VEC --> ECS[entity_card: 角色/地图/世界观]
VEC --> INF[inference]
VEC --> MYS[mystery]
end
DB -.全量重建/增量更新.-> VEC
BLOB -.全量重建/增量更新.-> VECflowchart TB
subgraph FACT[事实层(Source of Truth)]
DB[(data/novel.db)]
BLOB[data/blob_store/]
DB --> CH[chapters / drafts]
DB --> KV[kv_store]
DB --> REL[关系表(characters/organizations/...)]
end
subgraph INDEX[索引层(可重建)]
VEC[(data/vector_db/)]
VEC --> CHS[chunks: source_type=chapter]
VEC --> ECS[entity_card: 角色/地图/世界观]
VEC --> INF[inference]
VEC --> MYS[mystery]
end
DB -.全量重建/增量更新.-> VEC
BLOB -.全量重建/增量更新.-> VEC2.3 具体实现
1) 选型:ChromaDB(本地持久化 + 开箱即用)
我选择 ChromaDB 的原因很朴素:它能在本地持久化,并且把“collection + HNSW”这套索引能力封装得足够简单,适合先把闭环跑通。
关键点:
- 持久化客户端:
chromadb.PersistentClient(path="data/vector_db") - collection:
novel_chunks - 距离空间:
cosine(余弦相似度)
2) Embedding:本地 HuggingFace + 在线兜底
理想状态下,我用本地 HF 模型做 embedding(mean pooling + normalize),尽量减少线上依赖。
但在树莓派这种 ARM 环境里,工程上经常会遇到一个现实问题:某些 torch/推理库的二进制轮子与 CPU 指令集不兼容,运行时会直接 Illegal instruction 硬崩溃(无法 try/except)。
因此当前实现提供“多后端”:
- 本地 HF/torch:最省调用成本,适合 x86/Linux 或已验证兼容的环境
- OpenAI Embedding(远程):在 ARM 环境下作为稳定兜底(代价是联网与 embedding 调用费用)
3) 分块:语义分块(按段落/句子边界优先)
为什么要分块?因为一章可能几千到几万字,你需要“更小粒度的可召回片段”,否则向量检索会召回一大坨文本,既不准也塞不进上下文。
早期我用过“固定字符滑动窗口 + 重叠”的基线方案,但在小说语境下容易把对白/动作链条硬切断,导致召回片段缺上下文。
现在我升级为“语义分块”:
- 优先按段落切分:以空行作为自然边界,把段落拼装成接近目标长度的 chunk
- 长段落再按句号/问号/感叹号切:尽量保持句子完整
- 轻量 overlap:按“段落级别”做 1 段重叠,尽量保住对白/动作的承接
长篇小说还有一个“向量检索特有”的坑:代词上下文(他/她/它)。如果一个 chunk 恰好从“他拔出了剑”开始,召回时模型可能不知道“他”是谁。未来可以做两类增强:
- 在 metadata 里挂上该 chunk 的
primary_character_id(或主视角角色),用于检索后“按主角/视角过滤或加权” - 或在 chunk 文本头部自动补一个极短的“指代提示”(例如“此段主视角:XXX”),降低上下文污染
分块与更新逻辑放在“章节保存成功之后”的同步流程里,确保索引不会滞后于正文。
4) “挂靠实体”的索引设计:ID 与 metadata
向量检索一定要能回溯到“它来自哪里”,否则结果不可解释、不可维护。
当前我把每个 chunk 的身份写清楚:
- id:
ch_{chapter_ulid}_{chunk_index}(避免标题改名导致索引漂移) - metadata:
chapter_idchapter_ulidchapter_titlechunk_indexsource_type="chapter"
这让我可以做 where={"chapter_title": ...} 这种过滤,也能把检索结果明确展示为“来自哪章哪一段”。
(未来如果要扩展到实体卡片、推测、未填坑等,只需要在 metadata 增加 entity_type/entity_id,并把 chunk 来源从“章节”拓展为“任意实体”。)
5) 更新策略:章节更新时“先删后写”,保证一致性
向量库是索引层,最怕“索引没更新导致召回旧内容”。因此我采用简单可靠的策略:
- 保存章节成功后:
- 优先
delete(where={"chapter_ulid": ...})(无 ulid 时退化为按标题删) - 重新分块
- batch add 写入
- 优先
这样更新是幂等的,逻辑清楚,也便于排错。
6) 两种重建方式:增量更新 + 全量初始化
为了可运维,我保留两条路径:
- 增量更新:日常写作保存章节时自动更新向量库(同上)
- 全量重建:从
novel.db读取所有章节,reset collection 后重建索引
7) 检索入口:从 ContextManager 到 UI
检索调用链是:
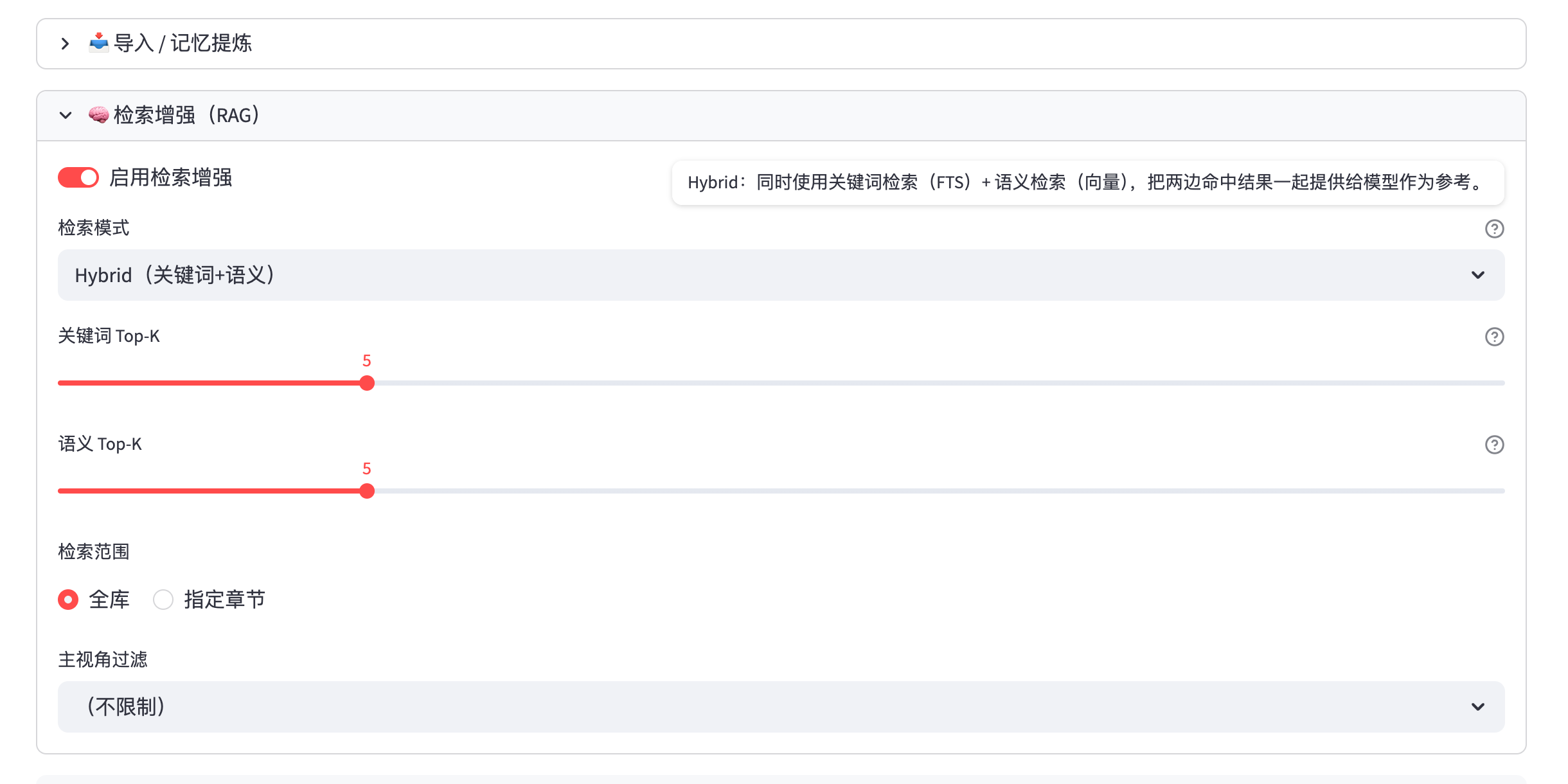
ContextManager.search_vectors()→VectorManager.search()- UI 在主窗口提供“检索增强(RAG)”面板:支持 Hybrid(关键词+语义)/ 仅关键词(FTS)/ 仅语义(向量),并展示最近一次命中片段
2.4 向量库能解决什么,不能解决什么
向量库擅长的
- 模糊召回:找“相似情绪/相似冲突/相似描写”
- 超长书的记忆外挂:从几十万字里快速找回相关片段,拼进上下文
- 风格与人物说话习惯:用“过去的对话片段”帮助模型模仿口癖与语气
向量库不擅长的(仍需要关系表)
- 确定性状态:主角当前境界是金丹还是元婴,这是 exact match,不能接受模糊
- 事务性更新:物品转移、所属变更需要原子性和一致性
- 结构化筛选:例如“所有属于青云门且存活的弟子”,SQL 一条语句精准得出
最好的组合方式始终是:
- 关系表(左脑):事实、状态、关系网、时间线
- 向量库(右脑):联想、氛围、语义相似、记忆召回
3. 混合检索与全图谱:让 AI 拥有“完整记忆”
现在的数据层已经是一个清晰的分层系统:
data/novel.db:事实来源(结构化数据/元数据/KV/FTS)data/blob_store/:事实来源(章节正文对象,按 ulid)data/vector_db/:语义检索索引(可重建)
这意味着系统不再只是“能存、能查”,而是开始具备“能召回、能拼装上下文”的完整检索能力。
3.1 混合检索:FTS5(查照)+ 向量(语义)
向量检索解决“像不像”,FTS5 解决“出现没出现”。它们天然互补。
目前我在主窗口把两者并列成“索引层双引擎”,并提供 Hybrid/仅关键词/仅语义三种模式切换。
更重要的是:这不是“简单拼接两个结果”。在工程上,一个常见误区是“级联过滤”:先 FTS 得到候选集,再只在候选集里做向量检索。它省算力,但也有风险:
- 例如我搜“一种绝望的心情”,FTS 可能一个字都匹配不到,候选集为空;但向量检索本来能召回“心灰意冷”的段落。
因此我采用的整体思路是“并行检索 + 融合排序”:
- 向量检索(全库):先跑一遍语义召回,保证“联想能力不被关键词卡死”
- FTS(关键词):同时跑一遍查照,保证人名/地名/法宝等确定性命中
- 融合(Fusion):对召回结果做一个轻量融合排序(例如 RRF,Reciprocal Rank Fusion),让“同时命中关键词 + 语义相似”的条目自然排到前面
同时我也保留“FTS 候选→候选内向量召回”的优化路径:当 FTS 能命中到明确候选章节时,可以只在候选章节里做更精细的向量召回,再与全库向量召回融合,兼顾速度与质量。
3.2 FTS5 的同步方式:从触发器到应用层更新
为了适配正文拆分到 blob store的架构,我把 chapters_fts 的同步方式调整为:由 save_chapter() 做“手动更新”,而不是依赖触发器自动同步。
这样做的核心好处是:检索层不再被数据库内部触发器强绑死;即便正文存储形态调整,索引仍然可以在应用层以明确、可控的方式维护。
3.3 把向量“挂靠实体 ID”,从章节拓展到全图谱
之前向量库只存了章节 chunk,现在我把索引扩展到了整个实体语义网络:
- 章节 chunk:
source_type="chapter"(带chapter_id/chapter_ulid/chapter_title/chunk_index) - 实体卡片 chunk:
source_type="entity_card"(当前覆盖角色/地图/世界观,带entity_type/entity_key) - 推测/未填坑条目:
source_type="inference"/source_type="mystery"(以条目文本作为可召回单元)
这样向量召回就能“一句话召回章节段落 + 相关实体卡片/推测/未填坑”,非常适合 RAG 上下文拼装。
这个变化看似“只是多索引了一些文本”,但对写作系统意义很大,因为它把检索从“只会找原文”升级为“能把世界观一起带回来”:
- 我问一个名词/线索(例如某法宝、某势力、某角色),系统不仅能召回它出现在哪段正文里
- 还能同时召回对应的角色卡/地点卡/世界观片段,以及相关推测/未填坑
最终效果是:RAG 不再是“章内检索外挂”,而是开始具备“全书知识图谱的可召回视图”。
4. 未来展望:云化迁移预留
如果说前面的演进解决的是“单机可用、越写越稳”,那么下一步要解决的是:多设备同步、可长期运行、可随时访问。
4.1 云服务的本质需求是什么?
一个写作系统上云,核心不是为了“高并发”或“海量用户”,而是为了:
- 事实层可并发写入且能同步:不能再靠“同步整个 db 文件”来赌运气
- 索引层可重建但要随时可用:embedding 升级、索引损坏、模型切换都不能影响事实一致性
- API 化与权限:任何设备都用 HTTP 调用;鉴权/配额/日志要可控
- 低运维成本:不想维护一台服务器,不想管容器、升级和备份脚本
4.2 主流云厂商能提供什么?
把需求映射到云产品,基本就是三类能力:
- 计算(API/编排):Serverless Functions / Edge Functions / Cloud Run
- 关系型数据(事实层):托管 Postgres/MySQL 或云原生 SQL
- 向量检索(索引层):托管向量库或把 embeddings 放进数据库(pgvector 等)
对应到常见方案:
- AWS:Lambda + RDS(或 Aurora)+ 向量/检索服务生态,功能强但配置复杂,且关系库常有“空闲也计费”的心理负担
- Google Cloud:Cloud Run + Cloud SQL / Firestore + Vertex AI,开发体验不错,但对个人项目而言配套偏“重”
- Supabase:托管 Postgres + pgvector 非常自然,生态成熟;但免费层有暂停机制,部分场景冷启动会影响体验
4.3 云化路线:优先考虑 Cloudflare(D1 + Vectorize + Workers)
我打算未来把本项目从“单机工具”升级为“可在线访问、可多设备同步、可长期运行”的服务形态。结合当前工程(data/novel.db + data/blob_store/ + 向量索引),我会优先考虑迁移到 Cloudflare 的一组托管服务,把“事实层”和“索引层”拆开上云:
- 关系表:从本地 SQLite 迁到 Cloudflare D1(serverless SQL,按读写行数计费;免费档有日限额与存储额度)
参考:D1 定价 - 正文对象存储:章节正文属于“大文本”,已从数据库迁出并以对象形式存储(本地为
data/blob_store/)。上云时建议迁移到 Cloudflare R2(S3 兼容对象存储),D1 仅保留chapters.ulid/content_key等元数据与可检索摘要字段,以降低数据库体积与写入压力。 - 向量库:从本地 Chroma 迁到 Cloudflare Vectorize(免费档对 index/namespace/每个 index 的向量数量等有上限,更适合个人/小规模作品的语义检索)
参考:Vectorize Limits - 检索编排:把“检索融合逻辑”(FTS/结构化过滤/向量 rerank)放到 Cloudflare Workers 上运行;免费档有请求量与 CPU 时间限制,需要按实际访问量评估
参考:Workers 定价/免费档说明
这条路线的关键仍然是:D1/R2/对象存储承载事实数据,Vectorize 承载可重建的向量索引层,避免“索引变成第二套事实来源”。
如果未来确定要走 Postgres 生态(例如需要复杂 SQL、生态工具链或更强事务能力),再把关系表迁到 Postgres,并用 pgvector 存 embeddings 也是自然的下一跳:embedding 存 vector(n) 列,建 HNSW/IVFFlat 索引,与业务表 join 更方便。
5. 小结
这篇文章讲的是一件事:把“会记忆”落到“能检索”。
- 关系表负责确定性事实,向量索引负责语义联想
- FTS5 负责查照,混合检索负责把两者变成稳定体验
- 索引从章节扩展到全图谱,让 RAG 上下文不再只会“翻原文”
如果你想先从事实层开始读,建议从《实战 · 打造会记忆的AI 写作搭档(二):数据库篇(从 JSON 到单库,再到关系表)》开始。