实战 · 打造会记忆的AI 写作搭档(四):可观察性(Metrics + Logs + Trace + Cost)
在上一篇中,我们讨论了 RAG 系统的安全性与 Prompt 注入防护。今天我们来聊聊另一个工程化深水区:可观察性(Observability)。
当系统从“能跑”走向“长期可用”,你一定会遇到三类问题:
- 慢:检索慢?LLM 慢?还是某个 Agent 在疯狂重试?
- 贵:Token 消耗是不是被某条链路悄悄吃掉了?为什么这个月的 API 账单对不上?
- 怪:偶发 Bug 无法复现,只能靠“感觉”改代码。
在这个阶段,我选择建立一套完整的 Metrics(指标) + Logs(日志) 体系,而不是仅仅打印几行 print。
1. 监控体系概览
本项目的可观测性包含两部分,目标是覆盖“宏观健康度”与“微观可追溯性”:
- Metrics:基于 Prometheus,回答“现在总体是否健康?瓶颈在哪?”。
- Logs:基于结构化 JSON + OTLP,回答“这次具体发生了什么?原因是什么?”。
架构图
graph TD
App[FantasyNovelAgent] -->|Push/Pull| Prom[Prometheus/Grafana Cloud]
App -->|OTLP HTTP| Loki[Loki/Grafana Cloud Logs]
App -->|File| LocalLog[data/logs/app.log]
App -->|File| UsageStats[data/logs/usage_stats.json]graph TD
App[FantasyNovelAgent] -->|Push/Pull| Prom[Prometheus/Grafana Cloud]
App -->|OTLP HTTP| Loki[Loki/Grafana Cloud Logs]
App -->|File| LocalLog[data/logs/app.log]
App -->|File| UsageStats[data/logs/usage_stats.json]graph TD
App[FantasyNovelAgent] -->|Push/Pull| Prom[Prometheus/Grafana Cloud]
App -->|OTLP HTTP| Loki[Loki/Grafana Cloud Logs]
App -->|File| LocalLog[data/logs/app.log]
App -->|File| UsageStats[data/logs/usage_stats.json]graph TD
App[FantasyNovelAgent] -->|Push/Pull| Prom[Prometheus/Grafana Cloud]
App -->|OTLP HTTP| Loki[Loki/Grafana Cloud Logs]
App -->|File| LocalLog[data/logs/app.log]
App -->|File| UsageStats[data/logs/usage_stats.json]2. Metrics:用最少的维度回答最关键的问题
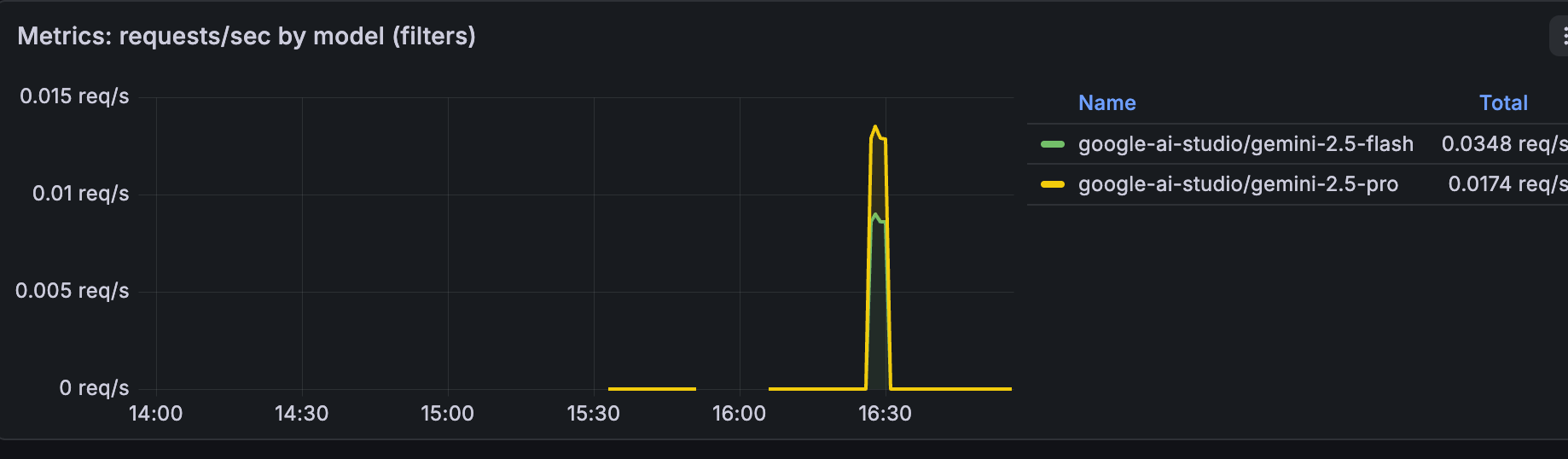
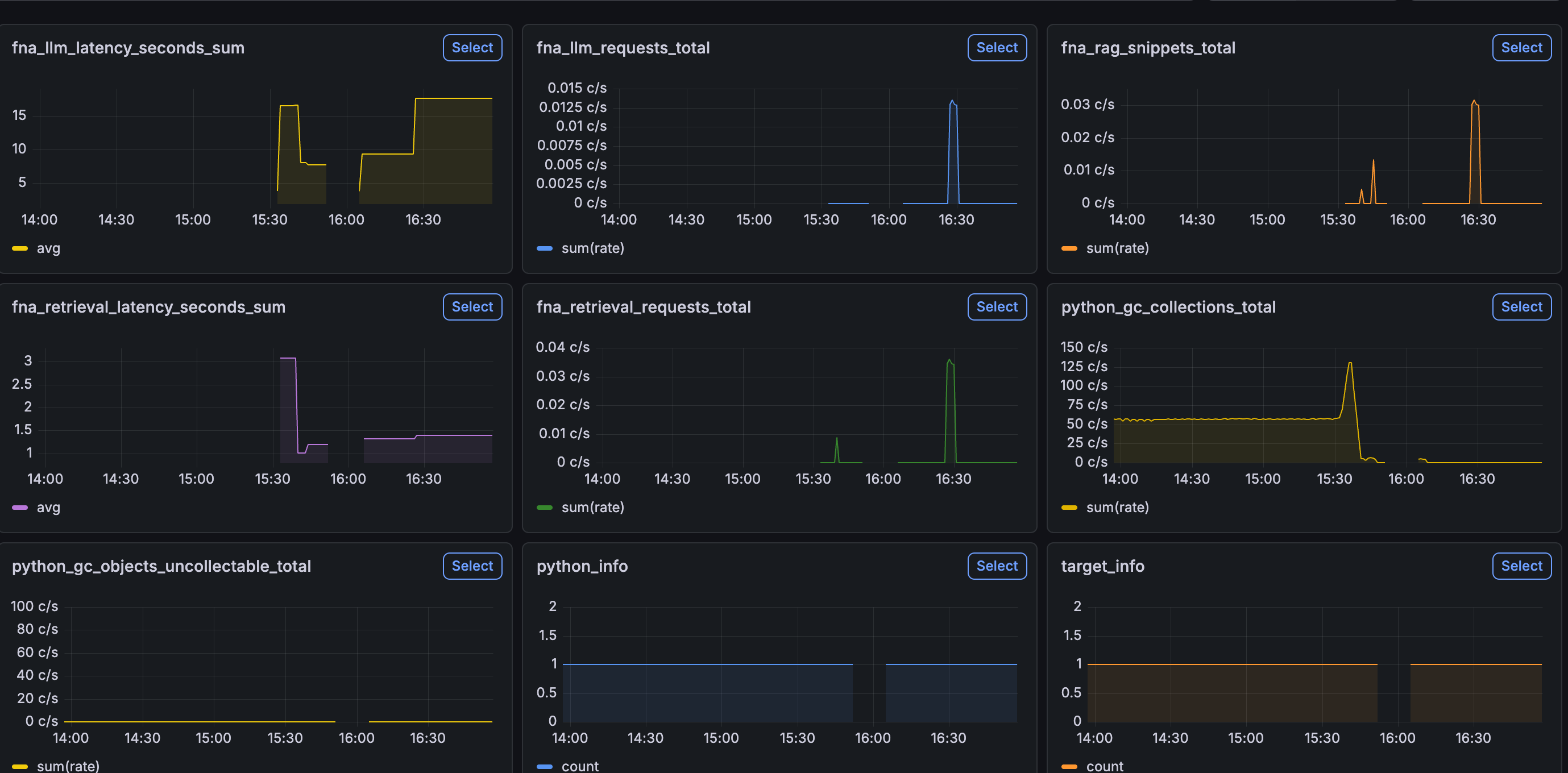
系统通过 Prometheus Client 暴露指标(默认端口 9108),或通过 OTLP 推送。我设计了一组 fna_* 前缀的自定义指标,涵盖了 AI 系统最核心的关注点。
2.1 核心指标设计
A. LLM 调用:耗时与 Token
AI 系统的核心开销都在 LLM。我们需要知道每个 Agent、每个模型、每个 Provider 的表现。
fna_llm_requests_total{agent,model,provider,status}:调用次数。fna_llm_latency_seconds_bucket:耗时分布。fna_llm_tokens_total{kind="prompt|completion|total"}:Token 消耗。
用途:
- 监控 API 错误率(如 429 限流、5xx 错误)。
- 对比不同模型的响应速度(Latency P95)。
- 实时计算 Token 消耗速率(Cost/Min)。
B. RAG 检索:命中与风险
检索是 RAG 的生命线。
fna_retrieval_requests_total{op,status}:检索次数(op=hybrid/vector/fts)。fna_retrieval_latency_seconds_bucket:检索耗时。fna_rag_snippets_total{trust_tier,risk,action}:检索片段审计。
用途:
- 监控检索性能:如果
search_hybrid突然变慢,可能是向量库有问题。 - 监控内容安全:观察
action=drop或action=redact的比例,判断是否存在注入攻击或低质量检索源。
C. 业务流与重试
用户体验取决于“端到端”的耗时,而不仅仅是单一函数。
fna_flow_latency_seconds_bucket{flow}:关键链路(如draft,brainstorm)的总耗时。fna_agent_call_retries_total:Agent 重试次数。fna_fact_guard_blocks_total:事实冲突拦截次数。
用途:
- 发现“隐形卡顿”:用户感觉慢,但 LLM 很快?可能是 Agent 在后台疯狂重试(Retry Loop)。
2.2 端口自动猎取(Port Hunting)
本地开发时最常见的“玄学问题”之一,是 Streamlit 的热重载(Hot Reload)或多进程模型导致旧实例未退出,从而出现端口占用:你以为新版本起来了,实际上你访问的是旧进程。
为降低这种排障成本,系统在启动 Metrics Server 时不会死守单一端口,而是按端口段自动尝试:
- 端口段:从
9108开始,尝试9108~9139,选取第一个可用端口。 - 残留处理:遇到端口被占用会自动换下一个,避免“因为僵尸实例导致完全起不来”。
- 排障建议:当你看到多个端口似乎都能访问时,以日志中的
event=metrics_started为准——它记录了本次进程最终绑定的端口,能快速定位“当前活着的实例”。
3. Logs:结构化与全链路追踪
日志输出为 JSON 行(JSON Lines),落盘到 data/logs/app.log,并支持通过 OTLP 上报。
3.1 为什么不用 Print?
传统的文本日志(User clicked button)在 AI 系统里很难分析。结构化日志(Structured Logging)将关键信息放入 JSON 字段,便于聚合查询。
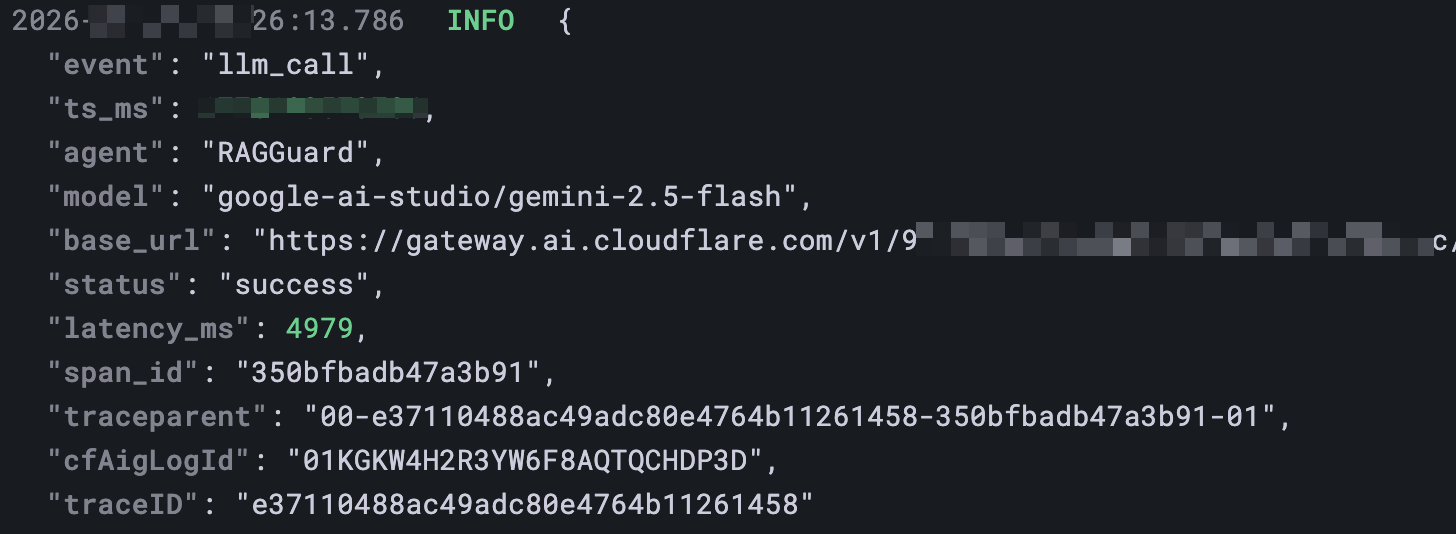
例如一条 llm_call 日志:
3.2 关键事件 (Event Schema)
我定义了几类关键事件,用于串联整个系统行为:
app_started/metrics_started:生命周期事件。llm_call/llm_error:LLM 交互详情(含 TraceID、Latency、Token)。rag_audit:RAG 审计(Query、命中片段数、风险等级)。- 隐私保护:开启“敏感模式”后,Query 采用“有限可见”策略:仅保留前 5 个字符用于基本识别,同时记录原始长度与 SHA-256 哈希,避免隐私泄露(详见:安全篇:隐私合规的日志治理)。
fact_guard_block:事实一致性拦截(拦截了什么冲突)。flow:业务流结束(状态、总耗时)。
3.3 全链路追踪 (Trace Context)
一开始,我规划的是“全链路单一 ID”:本地日志、OTLP、AI Gateway 都用同一个 trace_id 去检索,像排查传统微服务链路那样一路串到底。
但落地时遇到现实约束:查 Cloudflare AI Gateway 的文档后才发现,网关侧日志强制使用自研的 cf-aig-log-id 作为主键。也就是说,应用层无法把网关的“主 ID”改成我们自己的 trace_id。
最后我选择放弃理想化的“单一 ID”,转而实现一套 显式映射(ID Bridge):
- 请求头注入:对外请求携带
traceparent(W3C Trace Context)与cf-aig-otel-trace-id,让网关侧的 OTEL/Loki 日志里也带上可检索的关联键。 - 响应头捕获:从响应头读取
cf-aig-log-id,并记录到本地结构化日志字段(例如llm_call.cfAigLogId),作为“从应用跳到网关后台”的直达钥匙。
flowchart LR
subgraph APP[FantasyNovelAgent(应用侧)]
L[本地结构化日志
llm_call / llm_error
trace_id + cfAigLogId]
end
subgraph GW[Cloudflare AI Gateway(网关侧)]
W[网关日志主键
cf-aig-log-id]
end
subgraph OBS[Grafana(OTLP / Loki)]
G[日志聚合与检索
trace_id / cf-aig-otel-trace-id]
end
L -->|请求头注入
traceparent
cf-aig-otel-trace-id| W
W -->|响应头返回
cf-aig-log-id| L
L -->|OTLP 上报
trace_id| G
W -->|OTEL 兼容
携带 cf-aig-otel-trace-id| Gflowchart LR
subgraph APP[FantasyNovelAgent(应用侧)]
L[本地结构化日志
llm_call / llm_error
trace_id + cfAigLogId]
end
subgraph GW[Cloudflare AI Gateway(网关侧)]
W[网关日志主键
cf-aig-log-id]
end
subgraph OBS[Grafana(OTLP / Loki)]
G[日志聚合与检索
trace_id / cf-aig-otel-trace-id]
end
L -->|请求头注入
traceparent
cf-aig-otel-trace-id| W
W -->|响应头返回
cf-aig-log-id| L
L -->|OTLP 上报
trace_id| G
W -->|OTEL 兼容
携带 cf-aig-otel-trace-id| Gflowchart LR
subgraph APP[FantasyNovelAgent(应用侧)]
L[本地结构化日志
llm_call / llm_error
trace_id + cfAigLogId]
end
subgraph GW[Cloudflare AI Gateway(网关侧)]
W[网关日志主键
cf-aig-log-id]
end
subgraph OBS[Grafana(OTLP / Loki)]
G[日志聚合与检索
trace_id / cf-aig-otel-trace-id]
end
L -->|请求头注入
traceparent
cf-aig-otel-trace-id| W
W -->|响应头返回
cf-aig-log-id| L
L -->|OTLP 上报
trace_id| G
W -->|OTEL 兼容
携带 cf-aig-otel-trace-id| Gflowchart LR
subgraph APP[FantasyNovelAgent(应用侧)]
L[本地结构化日志
llm_call / llm_error
trace_id + cfAigLogId]
end
subgraph GW[Cloudflare AI Gateway(网关侧)]
W[网关日志主键
cf-aig-log-id]
end
subgraph OBS[Grafana(OTLP / Loki)]
G[日志聚合与检索
trace_id / cf-aig-otel-trace-id]
end
L -->|请求头注入
traceparent
cf-aig-otel-trace-id| W
W -->|响应头返回
cf-aig-log-id| L
L -->|OTLP 上报
trace_id| G
W -->|OTEL 兼容
携带 cf-aig-otel-trace-id| G调试流程也因此变成三段式:
- 本地查日志:先定位
llm_call/llm_error,拿到trace_id(以及对应的traceparent)。 - Grafana 查全链路:用同一个
trace_id(或cf-aig-otel-trace-id)在 OTLP/Loki 里把相关日志聚合出来。 - 网关查明细:把本地日志里记录的
cfAigLogId复制到 Cloudflare 控制台搜索,回看网关观测到的请求与响应细节。
4. 成本对账:从“本地账本”到“云端审计”
除了 Metrics 和 Logs,还有一个非常现实的需求:对账。在实战里,我经历了从“自研本地统计”到“接入云端网关”的认知演进:前者解决工程侧的最后三公里,后者把成本监控这件事交给专业基础设施。
4.1 本地记账:为 UI 与并发环境而生
项目会将每次 LLM 调用的 Token 用量追加到 data/logs/usage_stats.json。
即使接入了云端监控,本地记账文件依然不可或缺,它主要解决两类工程问题:
- 并发一致性(Atomic Writes):在 Streamlit 多进程或热重载(Hot Reload)场景下,旧进程往往未完全退出,新进程又开始写入。这里采用 文件锁(File Lock) + 临时文件原子替换 的策略,确保在极端竞争下 JSON 账本不损坏。
- UI 响应性:Streamlit 侧的“📊 模型用量统计”面板需要秒级加载。通过本地聚合这个小型 JSON,可以无需调用外部 API 就让作者实时看到:哪个 Agent 是“吞金兽”?上下文瘦身(Context Pruning)策略是否生效?
文件结构示例:
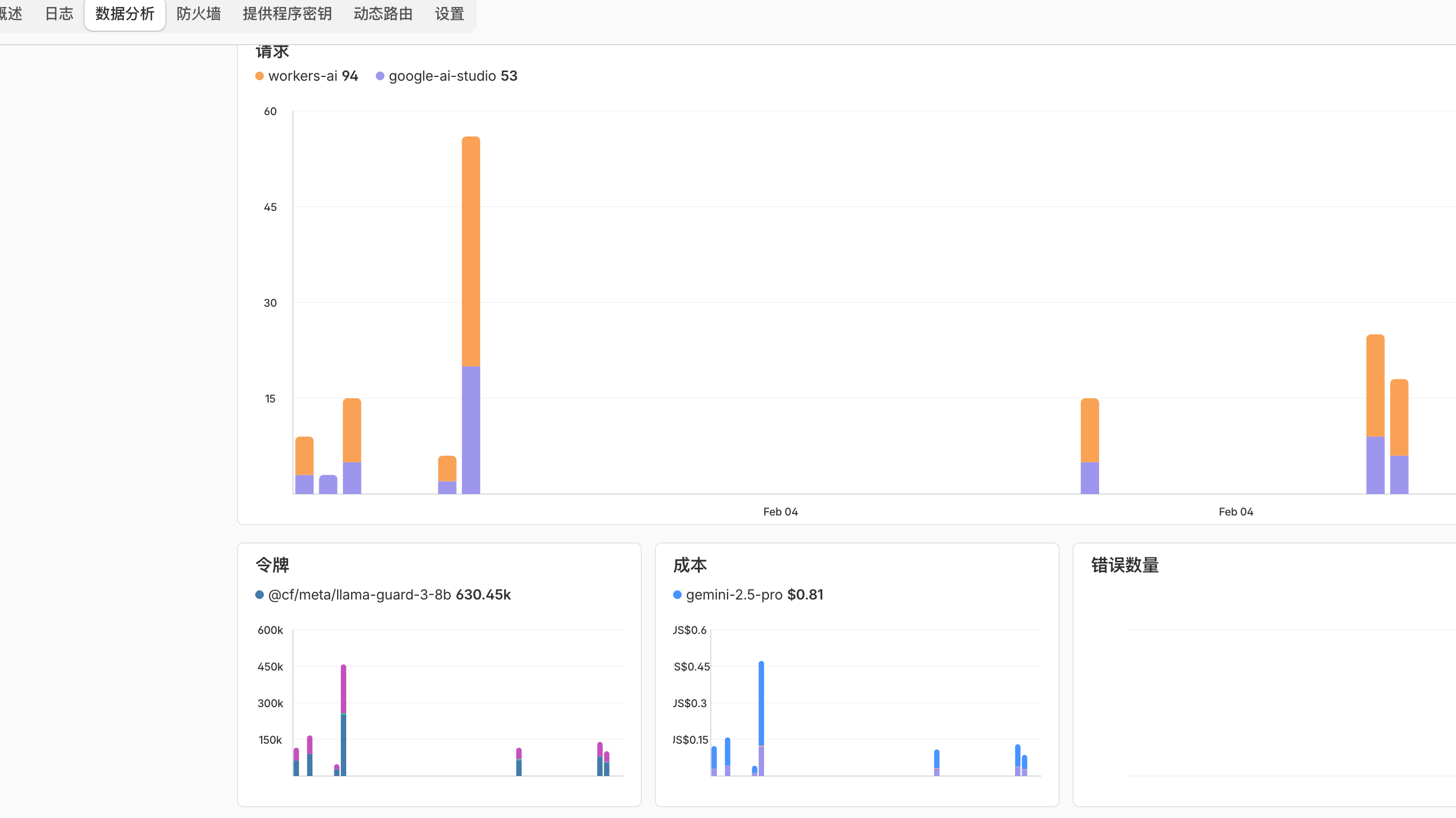
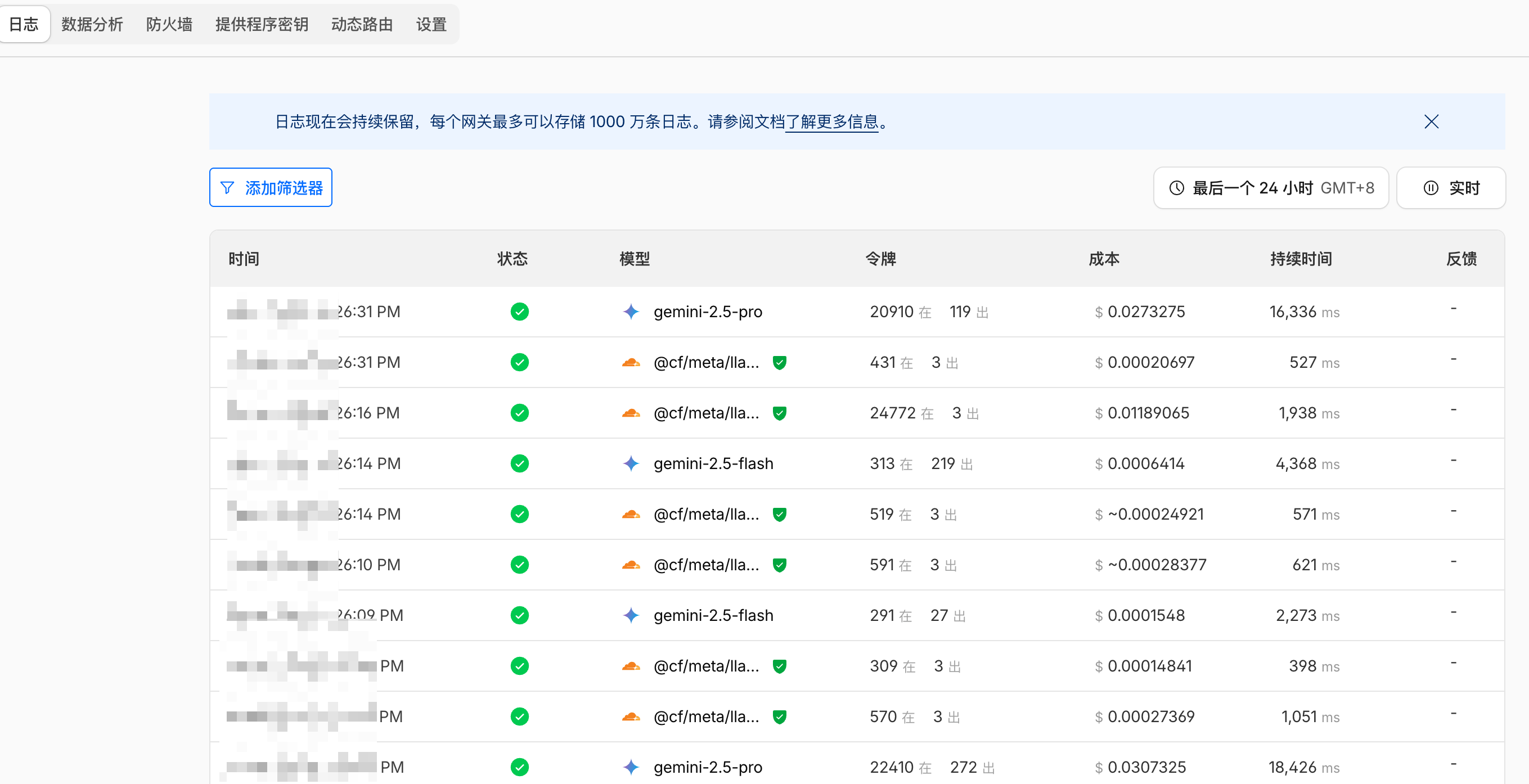
4.2 云端审计:Cloudflare AI Gateway 的观测降维
真正的“对账效率”提升来自基础设施接入:当 LLM 流量统一经过 Cloudflare AI Gateway 后,成本监控就不需要再靠本地脚本拼出来了。
- 天然 Dashboard:按模型、按时间、按费率等维度的可视化是开箱即用的,省掉了“聚合 JSON + 自绘图表”的维护成本。
- 事实来源前移:网关位于出网边界,更接近“真实的计费视角”。当你需要和账单对齐时,云端审计往往比应用内统计更稳、更可复核。
- 本地与云端分工:本地账本负责开发体验与并发可靠性;云端审计负责全局趋势与账单核对。两者不是重复建设,而是各自覆盖不同的可观测性半径。
5. 隐私与脱敏
在可观测性中,隐私保护至关重要。我们不希望用户的私密小说内容或 Prompt 出现在 Grafana 的大屏上。
本地与外发分离策略
这套“本地更详细、外发更克制”的策略在上一篇安全篇也有完整展开(RAG 审计敏感模式、对外上报白名单与脱敏),可对照阅读:实战 · 打造会记忆的AI 写作搭档(三):安全架构(RAG 防护、事实守卫与 BYOK)。
本地日志(data/logs/app.log):
- 默认保留较多细节,便于本地 Debug。
- 支持开启 RAG 审计敏感模式:Query 不保存全文,仅保留前 5 个字符,并记录原始长度与 SHA-256 哈希。
外发日志(OTLP/Loki):
- 按事件精细化脱敏:支持开启“对外上报日志脱敏”,采用“总开关 + 事件白名单(
enabled_events)”控制,默认仅对rag_audit与llm_call生效,其他事件不做脱敏以保留排查能力。 - 白名单机制:只允许特定事件(如
llm_call,rag_audit)上报,其他 Debug 日志拦截在本地。
- 按事件精细化脱敏:支持开启“对外上报日志脱敏”,采用“总开关 + 事件白名单(
6. 闭环:可观察性驱动的架构优化(上下文瘦身)
可观测性的价值不只是“看见问题”,更重要的是能把优化变成可验证的工程闭环。
一个典型案例是“上下文瘦身”:通过 world_cards / future_plan_cards 等结构化卡片把可复用信息从 prompt 主体抽离,减少 prompt_tokens,从而降低成本并提升稳定性。
如何量化验证这件事“真的省钱”:
- 看 Metrics:观察
fna_llm_tokens_total{kind="prompt"}的趋势(同类任务、同模型、同 Agent 前后对比)。 - 看成本对账文件:对比
data/logs/usage_stats.json中同一profile_id的prompt_tokens/total_tokens分布,能直接反映策略生效程度。
当你能用指标和对账数据证明“结构化卡片策略确实降低了 prompt_tokens”,这就从“经验主义调参”升级成了“数据驱动的架构设计”。
7. 结语:从黑盒到白盒
构建 AI 应用,特别是复杂的 Agent 系统,往往像是在炼丹——扔进去一堆 Prompt,等着出来一个结果。
通过引入 Metrics 和 Structured Logs,我们试图把这个“黑盒”变成“白盒”:
- 看见延迟:知道是向量库卡了,还是模型卡了。
- 看见成本:知道每一分钱花在了哪个 Agent 上。
- 看见风险:知道系统拦截了多少次潜在的注入攻击。
只有“看见”了,才能优化。这才是工程化落地的坚实底座。